

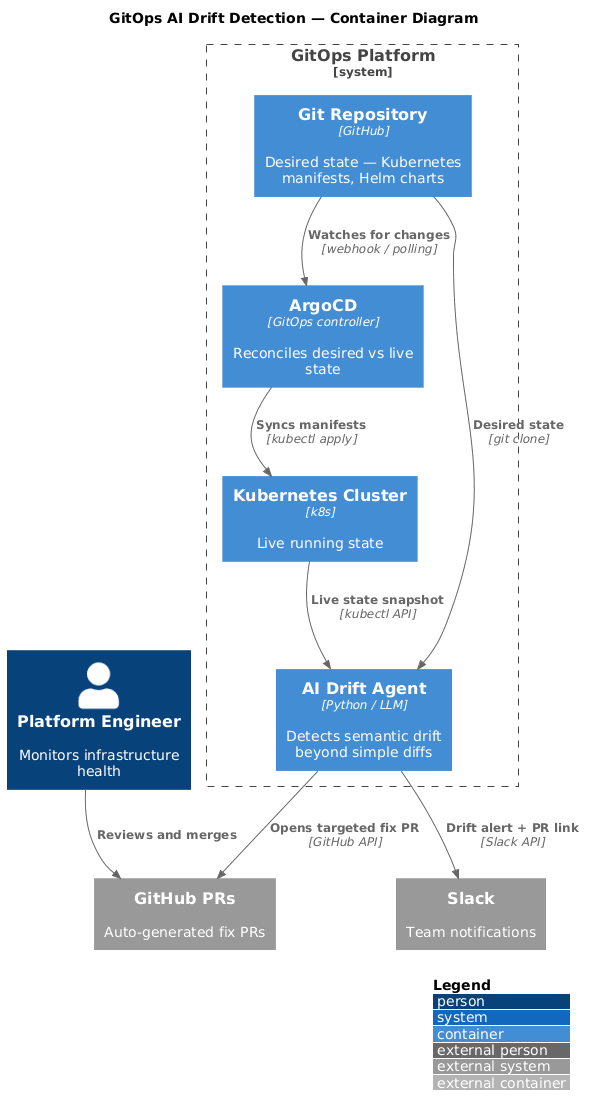
You know that moment when someone patches a ConfigMap at 2am, the fix works, everyone goes back to sleep, and nobody opens a PR? Three weeks later the next deploy reverts it. The incident repeats. And nobody immediately knows why, because the change lived only in the cluster, never in Git.
That's drift. And honestly, it's not a discipline problem — it's a systems problem. Every team that gives engineers direct cluster access alongside automated sync will hit this eventually. The gap between what Git says and what's actually running is invisible until it hurts.
AI makes that gap visible. Not by adding more dashboards, but by turning drift detection into an automated loop that classifies what it finds and opens a targeted PR when something needs fixing.
Quick takeaways¶
- Drift is rarely all-or-nothing — most clusters have harmless and risky divergence coexisting at any given moment
- Classification matters more than detection — knowing which drift to act on is the genuinely hard part
- Fix PRs should be targeted, not bulk — one drift, one PR, one reviewer who actually has the context
- The loop runs on a schedule, not just on deploy — because drift doesn't wait for you to ship
What drift actually looks like¶
ArgoCD will tell you an Application is OutOfSync. What it won't tell you is whether that's because:
- someone patched a resource directly (risky — it'll silently revert on the next sync, and surprise everyone)
- a controller updated status fields (harmless — this is expected behaviour, leave it alone)
- a Helm chart generated slightly different output because a values file changed (worth reviewing, but not panicking about)
- a sidecar injector added annotations at admission (harmless — Istio and Linkerd do this constantly)
The OutOfSync noise problem
Without classification, every OutOfSync looks the same. Teams start ignoring the alerts. Real drift hides in the noise. And then the 2am ConfigMap situation happens again. Detection without classification is worse than useless — it trains your team to treat real signals as noise.
The detection loop¶
Run this on a schedule — every 30 minutes in non-prod, every 15 in prod. Set it and let it run.
1. Query ArgoCD for OutOfSync Applications
2. For each application: run kubectl diff against live cluster
3. Feed the diff to an AI classifier
4. Classifier labels each diff: harmless / needs-review / risky
5. For risky or needs-review: open a targeted PR with the fix
6. Post a summary to Slack
Apply this: why PRs, not auto-sync
Auto-sync reverts drift immediately. But it doesn't capture why it happened. The PR approach creates a record of what diverged and forces an actual conversation: is the cluster wrong, or is Git wrong? Sometimes Git is wrong. You want that question asked, and you want the answer in writing.
1) Querying ArgoCD for drift¶
#!/bin/bash
# scripts/detect-drift.sh
ARGOCD_SERVER=${ARGOCD_SERVER:-"argocd-server.argocd.svc"}
OUT_OF_SYNC=$(argocd app list --output json \
--server $ARGOCD_SERVER \
| jq -r '.[] | select(.status.sync.status == "OutOfSync") | .metadata.name')
for APP in $OUT_OF_SYNC; do
echo "Checking drift for: $APP"
argocd app diff $APP --server $ARGOCD_SERVER > /tmp/drift-$APP.diff
done
2) AI classification of the diff¶
# scripts/classify-drift.py
import anthropic
import sys
client = anthropic.Anthropic()
CLASSIFIER_PROMPT = """
You are a Kubernetes drift classifier. You will receive a kubectl diff showing
the difference between Git state (desired) and live cluster state (actual).
Classify each changed resource as one of:
- HARMLESS: controller-managed fields, status updates, injected annotations
- NEEDS_REVIEW: values changed by Helm or config, could be intentional or drift
- RISKY: manual edits to spec fields, security settings, resource limits, replicas
Output JSON: {"resources": [{"name": "...", "kind": "...", "verdict": "...", "reason": "..."}]}
"""
def classify_drift(diff_content: str, app_name: str) -> dict:
message = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
messages=[{
"role": "user",
"content": f"Application: {app_name}\n\nDiff:\n{diff_content}"
}],
system=CLASSIFIER_PROMPT
)
return message.content[0].text
if __name__ == "__main__":
app_name = sys.argv[1]
diff_file = sys.argv[2]
with open(diff_file) as f:
diff = f.read()
print(classify_drift(diff, app_name))
Three classification buckets
HARMLESS (skip), NEEDS_REVIEW (open a GitHub Issue), RISKY (open a PR immediately). Setting a confidence threshold below which you open an Issue instead of a PR keeps the signal clean — reviewers only see PRs for things the classifier is confident about.
3) Opening a targeted fix PR¶
When the classifier returns RISKY, the agent opens a PR that restores the Git state for that specific resource. Just that resource. Nothing else gets touched, nothing gets auto-applied. The PR is the decision point.
# scripts/open-fix-pr.py
import subprocess
import json
from github import Github
def open_drift_fix_pr(app_name: str, resource: dict, diff: str):
"""Open a PR for a single drifted resource."""
branch = f"drift-fix/{app_name}/{resource['kind']}-{resource['name']}"
# Create branch
subprocess.run(["git", "checkout", "-b", branch], check=True)
# The fix is recorded in the PR body, not applied as a code change
# (the sync itself is the fix - this PR is the review gate)
pr_body = f"""## Drift detected: {app_name}
**Resource:** `{resource['kind']}/{resource['name']}`
**Verdict:** {resource['verdict']}
**Reason:** {resource['reason']}
### What changed in the cluster
```diff
{diff}
Recommended action¶
Review whether the live state represents an intentional change that should be committed to Git, or whether the cluster should be synced back to Git state.
- If the cluster change was intentional: update the Git config and close this PR
- If it was accidental: approve this PR to acknowledge, then trigger ArgoCD sync
Generated by drift-detection workflow """
g = Github(os.environ["GITHUB_TOKEN"])
repo = g.get_repo(os.environ["GITHUB_REPO"])
pr = repo.create_pull(
title=f"[Drift] {app_name}: {resource['kind']}/{resource['name']}",
body=pr_body,
head=branch,
base="main",
draft=False
)
return pr.html_url
``` If you're wondering what governs these PRs before they merge — Kyverno admission policies, OPA Terraform checks, the whole validation layer — that's covered in Policy as Code + Agents.
4) GitHub Actions workflow¶
```yaml
.github/workflows/drift-detection.yml¶
name: GitOps Drift Detection on: schedule: - cron: '/30 * * * ' # every 30 minutes workflow_dispatch: jobs: detect-drift: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Install ArgoCD CLI run: | curl -sSL -o /usr/local/bin/argocd \ https://github.com/argoproj/argo-cd/releases/latest/download/argocd-linux-amd64 chmod +x /usr/local/bin/argocd - name: Detect drift env: ARGOCD_AUTH_TOKEN: ${{ secrets.ARGOCD_AUTH_TOKEN }} ARGOCD_SERVER: ${{ secrets.ARGOCD_SERVER }} run: bash scripts/detect-drift.sh - name: Classify and open PRs env: ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }} GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }} GITHUB_REPO: ${{ github.repository }} run: python scripts/classify-and-pr.py - name: Post summary to Slack if: always() env: SLACK_WEBHOOK: ${{ secrets.SLACK_WEBHOOK }} run: python scripts/post-drift-summary.py ```
What harmless drift looks like (skip these)¶
Some patterns are always safe to ignore. Hard-code them into your classifier so they never make it into a PR:
status.*fields (controller-managed — you didn't write these, you don't own them)metadata.resourceVersion,metadata.uid,metadata.creationTimestampmetadata.annotations["kubectl.kubernetes.io/last-applied-configuration"]- Sidecar containers injected by Istio or Linkerd
spec.nodeNameon Pods
Apply this ignore list from day one
If a field isn't in your Git manifests, a controller added it. That's not your concern. Don't waste reviewer attention on it. Building this ignore list into the classifier prompt is what keeps your PR volume manageable — without it, every Istio-injected annotation becomes a drift alert.
Common objections¶
"Won't this create too many PRs?"
Only if you have too much drift — which is actually the point. A noisy drift detector is telling you something real: your cluster isn't being managed the way you think it is. Don't silence the noise. Fix what's causing it.
"What if the PR-opener gets it wrong?"
Nothing happens to the cluster because a PR was opened. It's a review gate, not an auto-apply. Engineers look at it, decide, and act. If you want to understand the three-tier approval model for which of these PRs actually needs a human before merging, Agentic Change Management covers that in detail.
"ArgoCD auto-sync already handles this."
It reverts. But it doesn't explain. Auto-sync can't tell you whether the cluster was wrong or Git was wrong — it just picks Git. Sometimes that's right. Sometimes it quietly reverts an intentional hotfix. The PR forces the question to be asked, and gets the answer into the record.
Frequently asked questions¶
What is GitOps drift and how does it happen?
It's when the live state of your cluster diverges from what Git says it should be. Happens all the time: someone applies a change manually at 2am (bypassing GitOps entirely), a controller overwrites a field it owns, or an external process modifies a resource without anyone creating a corresponding commit. The scary part isn't that it happens — it's that it's invisible until something breaks.
How do you detect drift in ArgoCD automatically?
Query ArgoCD's API for anything with OutOfSync status on a schedule — every 30 minutes is a reasonable starting point. For each out-of-sync resource, pull the diff between desired and live state and run it through an AI classifier. The classifier tells you whether this needs a fix PR or whether you can safely ignore it. That classification step is what separates signal from noise.
What's the difference between harmless and dangerous drift?
Harmless drift is fields Kubernetes manages automatically and you'd never put in a manifest yourself — resourceVersion, uid, creationTimestamp, status fields, HPA-managed replica counts. Dangerous drift is the stuff that matters: manually applied security group changes, RBAC modifications, or config values that silently differ from what's in Git. The risk with dangerous drift is that it reverts on the next sync with no warning.
How do you prevent an AI agent from opening incorrect fix PRs?
Set a confidence threshold and don't open PRs below it. For medium-confidence cases, open a GitHub Issue for human review instead of a PR. And include the full diff plus the model's reasoning in every PR body — reviewers should be able to verify the classification themselves without trusting the agent blindly.
Is this compatible with multi-cluster ArgoCD setups?
Yes. The detection script runs against ArgoCD's API, which can manage multiple clusters. You scope the classifier per cluster by including the cluster name and environment in the classifier prompt — this lets it apply different risk thresholds (staging vs production) and different ignore lists per environment.
What you get¶
- Drift is visible within 30 minutes of occurring, not on the next 2am incident
- Every manual cluster edit creates a PR that forces someone to actually decide what to do
- The audit trail is in Git, where it belongs and where anyone can find it
- Engineers stop treating
OutOfSyncas noise because it's now classified and genuinely actionable
Walkthrough files¶
scripts/detect-drift.sh— query ArgoCD for out-of-sync appsscripts/classify-drift.py— AI classification of kubectl diff outputscripts/open-fix-pr.py— targeted PR creation per drifted resource.github/workflows/drift-detection.yml— scheduled detection workflow
For the change management layer that controls how these fix PRs actually get reviewed and merged, see Agentic Change Management.