

The Four Rules That Make AI Agents Actually Trustworthy¶
There's a repo on GitHub with over 100,000 stars and a single file in it.
No framework. No library. Just a CLAUDE.md — 65 lines of behavioural rules for AI coding agents, written by Andrej Karpathy and refined by thousands of contributors. It held the #1 spot on GitHub Trending for 28 consecutive days. And according to the engineers who've actually measured it, applying the four rules cuts AI coding mistakes from 41% down to 11%.
The number that made 100,000 engineers take notice
Karpathy's four rules reduced AI coding error rates from 41% to 11% across real production codebases. That's not a benchmark — it's a before/after from teams who added a 65-line file to their repo root.
The repo is called andrej-karpathy-skills, and if you haven't read it yet, stop here and go read it. It'll take four minutes.
Back? Good. Here's what struck me about it.
Those rules aren't just about code quality. They're about trust. And if you're a platform engineer who's been quietly worrying that the AI agents you're deploying might one day do something you didn't expect — rewrite a file you didn't ask them to touch, open a PR that goes further than it should, make a "helpful" change that breaks something adjacent — this document is the answer you've been looking for.
Let me walk through the four rules and show you exactly why they matter beyond the IDE.
How CLAUDE.md Fits Into Your Agent Workflow¶
Before we get into the rules, here's the architectural picture. CLAUDE.md isn't a tool — it's a discipline layer that sits between you and your agent, constraining how it behaves across every action it takes.
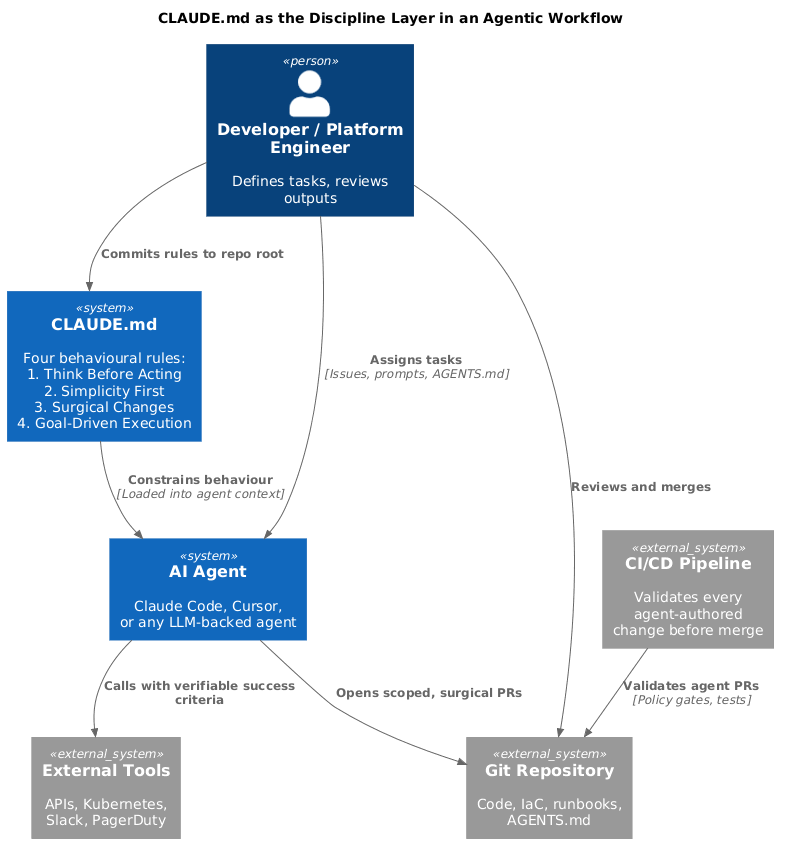
The key insight is that CLAUDE.md gets loaded into context before the agent does anything else. It's not a suggestion — it's the first thing the agent reads. Everything that follows gets filtered through those four rules. That's why 100,000 engineers put it in their repos.
Rule 1: Think Before Coding (or Acting)¶
Karpathy's first rule is blunt: don't assume. If the agent is uncertain, it should stop and say so. If multiple interpretations exist, surface them — don't silently pick one. If something is unclear, name it and ask.
This sounds obvious. It's almost never what happens by default.
The agents most of us deploy start doing the moment they have a task. That's the whole appeal — you give them a job and they get on with it. But there's a silent assumption baked into every agentic action: that the agent understood the intent correctly. And when it didn't? You find out later, usually from a diff that shows a change you didn't ask for, or a Slack message from a teammate asking why their config changed.
Here's the practical fix. In every agent workflow you design, build in an explicit planning step before any action is taken. Not a loop — a pause. Ask the agent to state what it understood the task to be, what it assumes is in scope, and what it'll leave alone. If it's using a tool that touches infrastructure — opening a PR, modifying a ConfigMap, calling an API — that statement should be visible somewhere before the action executes.
You don't need to make this interactive for every task. A structured output written to a log, a brief comment at the top of the PR, a plan.md file committed alongside the change — any of these work. The goal is that you can read it and immediately know whether the agent understood correctly.
If it didn't, you catch it there. Not three steps later.
Apply this in your AGENTS.md
Add a ## Before acting section to your AGENTS.md that requires agents to state their understanding of each task before executing. The walkthrough AGENTS.md at the end of this post includes a ready-to-use template.
Rule 2: Simplicity First¶
The second rule: minimum code that solves the problem. Nothing speculative. No abstractions for single-use code. No "flexibility" that wasn't requested.
Karpathy includes a check that I keep coming back to: "Would a senior engineer say this is overcomplicated? If yes, simplify."
For platform agents, this translates into something I'd call scope discipline. Every agent has a natural tendency to be helpful in ways you didn't ask for. You ask it to write a runbook section and it rewrites the whole document. You ask it to add a tag and it refactors the tagging structure. You ask it to diagnose a slow query and it proposes a schema change.
Each of these might be genuinely useful. That's not the point. The point is that the scope expanded without your consent.
The fix isn't to make agents dumber — it's to make their scope explicit at task creation time. In the repo-native AI workflow pattern, this means writing issue templates that spell out what's in scope and what isn't. The agent reads the issue, does exactly that thing, and opens a PR. The PR description echoes back what was in scope. If the agent noticed something adjacent that might be worth doing, it mentions it in a comment — it doesn't do it.
This is the "minimum viable change" principle applied to agentic work. It's not about limiting capability. It's about keeping diffs readable, keeping trust high, and keeping the feedback loop short.
The scope creep tell
If your agent's PR touches files that aren't mentioned in the task description, scope discipline has broken down. The walkthrough GitHub issue template has explicit "in scope / out of scope" fields that force this boundary at task creation time.
Rule 3: Surgical Changes¶
This one's my favourite because it describes the failure mode so precisely.
"Don't improve adjacent code, comments, or formatting. Don't refactor things that aren't broken. Match existing style, even if you'd do it differently."
And then this: "The test: every changed line should trace directly to the user's request."
That last sentence is a contract. If you can't point to the line in the user's request that caused a particular change, that change shouldn't be there.
For platform engineers, this rule has teeth when you're running agents that touch shared infrastructure. The agent that detects GitOps drift and opens a fix PR — does every line in that PR trace to the drift that was detected? Or did it also "clean up" some formatting, adjust a label it noticed was inconsistent, add a comment it thought would be helpful?
The drift detection pattern we use produces targeted PRs by design: the agent identifies the delta between live state and desired state and fixes exactly that delta. Nothing else. The diff is small. The reviewer knows what to look for. The PR merges quickly.
Agents that reach beyond their scope produce PRs nobody trusts enough to merge quickly, which defeats the whole point.
The surgical change test
Before merging any agent PR, ask: can every changed line be traced back to a specific sentence in the task description? If not, the agent over-reached. This isn't a failure — it's a signal that the task description needed tighter scope.
Surgical also applies to what agents leave behind. Karpathy's rule covers orphans: imports, variables, functions that your changes made unused should be removed — but pre-existing dead code should be left alone unless you were specifically asked to clean it up. The equivalent in infrastructure: if the agent's change made a resource reference obsolete, remove that reference. But don't audit and remove all the other stale references you noticed on the way through.
One thing at a time. On purpose.
Rule 4: Goal-Driven Execution¶
The final rule is the most operationally important one.
"Transform tasks into verifiable goals. Strong success criteria let you loop independently. Weak criteria require constant clarification."
Karpathy's example is sharp: "Fix the bug" is weak. "Write a test that reproduces the bug, then make it pass" is strong. The difference is that the strong version has a binary exit condition. The agent knows exactly when it's done.
This matters enormously for unattended agents. If an agent is running on a cron, responding to an alert, or triggered by a webhook — there's nobody watching. The agent needs to know what "done" looks like without asking. And if it hits something unexpected, it needs to know when to stop and escalate rather than continuing to try variations.
In the SLO-driven automation pattern, the success criteria are defined up front in the remediation catalogue: this action is complete when the SLO burn rate drops below the threshold within N minutes. If that doesn't happen, the agent escalates. It doesn't keep trying. The pre-approved catalogue defines what success looks like for each remediation action, so the agent can loop independently on the happy path and hand off cleanly when it can't reach the exit condition.
This is also where the agentic change management tier model connects. Tier 1 actions (low risk, pre-approved) have clear success criteria and run unattended. Tier 2 and 3 actions require human approval precisely because the success criteria are fuzzier — the agent can't verify correctness without a human in the loop. The tier model is really just a structured answer to: "how much do we trust this agent to know when it's done?"
Why These Four Rules Specifically¶
You might be thinking: these are pretty general. Don't all good engineering practices boil down to something like this?
Sort of. But here's what's different about Karpathy's framing.
These rules are written against the grain of how language models behave by default. A model that hasn't been given these constraints will naturally expand scope, add "helpful" features, refactor adjacent code, and continue trying variations rather than stopping and asking. The defaults are wrong for production use. These rules exist to correct them.
That's why 57,000 engineers starred this file. Not because the ideas are novel, but because they're the specific counter-forces you need to apply to get agents that behave like careful, disciplined colleagues rather than enthusiastic interns who haven't learned to ask before they do things.
If you're designing agentic workflows for your platform team, these four rules should be the first thing you embed — in your AGENTS.md, in your task templates, in your PR review process, in your remediation catalogue. Before you think about which tools the agent has access to, think about what constraints govern how it uses them.
The capability is almost never the problem. The discipline layer usually is.
FAQ¶
Is CLAUDE.md just for coding agents?
No, though that's where it originated. The four rules — think before acting, minimum scope, surgical changes, verifiable success criteria — apply to any agentic workflow where an AI is taking actions with real-world consequences. Infrastructure agents, doc update agents, triage agents: all of them benefit from these constraints.
Should I copy Karpathy's CLAUDE.md directly into my repo?
The file itself says "merge with project-specific instructions as needed" — which is the right framing. Use it as a base and extend it with context specific to your stack, your conventions, and your tolerance for autonomous action. The walkthrough CLAUDE.md at the end of this post is already extended for platform engineering teams specifically.
Does this mean agents should ask for permission constantly?
No — that's the opposite of useful. The goal is to design tasks clearly enough that the agent doesn't need to ask. The planning step in Rule 1 isn't interactive clarification; it's the agent stating its interpretation before acting so you can catch misunderstandings in the log rather than in the diff. For routine, well-scoped tasks, a well-constrained agent should be able to run completely unattended.
How do you enforce these rules technically?
You can't fully enforce them through prompting alone — the rules need to be backed by workflow design. Scope discipline comes from good task templates. Surgical changes come from code review and PR conventions. Goal-driven execution comes from pre-defined success criteria in your remediation catalogue or task definitions. The CLAUDE.md is the statement of intent; your tooling and process are what make it hold.
Karpathy's CLAUDE.md is worth keeping open in a tab while you design your next agentic workflow. Not because it'll tell you what tools to use or how to structure your pipelines — but because it'll keep asking you the question that matters most: does this agent know exactly what it's supposed to do, and exactly when to stop?
If you can answer yes to both, you've got something you can trust.
Walkthrough files¶
Everything from this post is ready to drop into your repository. All three files are in the ai-capabilities repo.
| File | What it is |
|---|---|
templates/CLAUDE.md |
Production-ready CLAUDE.md extended for platform engineering — adds blast radius awareness, approval tiers, and audit trail requirements on top of Karpathy's four core rules |
examples/karpathy-claude-md.md |
AGENTS.md routing map for agents in your repo — defines what's Tier 1 (autonomous), Tier 2 (draft PR), and Tier 3 (synchronous approval), plus which tools agents can use and what's explicitly out of scope |
templates/github-issue-agent-task.md |
GitHub issue template that enforces Rule 4 at task creation — forces explicit scope, success criteria, approval tier, and rollback plan before an agent picks up any task |
Drop templates/CLAUDE.md into your repository root as CLAUDE.md. Add examples/karpathy-claude-md.md as your AGENTS.md. Put the issue template in .github/ISSUE_TEMPLATE/agent-task.md. That's the minimum viable discipline layer.
For the workflow patterns that put these rules into practice at scale, start with Repo-Native AI Workflows for the task structure layer, Agentic Change Management for the governance tier model, and SLO-Driven Automation for what goal-driven execution looks like when the stakes are a production SLO breach.