

A2A and MCP Are Not Competing — They're the Stack¶
If you've been watching the MCP space, you've probably seen A2A mentioned in the same breath and wondered whether Google just launched a competing standard. They didn't. A2A and MCP divide the problem cleanly: MCP is how an agent talks to tools and data. A2A is how one agent talks to another. Once you see it that way, the question isn't "which one?" — it's "when do you need both?"

Quick takeaways¶
- A2A v1.0 is a stable spec for agent-to-agent task delegation — it defines how a client agent identifies a capable remote agent, hands off a task, and receives results asynchronously
- MCP handles agent-to-tool connections (Kubernetes, GitHub, databases). A2A handles agent-to-agent delegation across trust boundaries
- A2A uses HTTP, JSON-RPC 2.0, and SSE — nothing exotic. It fits naturally alongside your existing MCP infrastructure
- The key new primitive is the Agent Card — a signed JSON document that declares what an agent can do and how to reach it, analogous to MCP's Server Card
- 150+ organisations including AWS, Microsoft, Salesforce, SAP, and ServiceNow are running A2A v1 in production as of April 2026
What MCP doesn't solve¶
MCP is excellent at what it does: it gives an agent a standard way to connect to tools — Kubernetes, GitHub, databases, internal APIs. An agent with a well-configured MCP setup can query pods, open PRs, read runbooks, post to Slack. That's a lot of capability, and for many use cases it's all you need.
What MCP doesn't give you is a way for one agent to hand a task to another agent. If you want an incident triage agent to delegate a detailed Kubernetes diagnosis to a specialist K8s ops agent, and then hand the findings to a notification agent, you have a few options without A2A — and none of them are good:
- Monolithic agents: one agent handles everything. Prompt bloat grows with every new capability you add, it becomes impossible to test individual components, and swapping one part means redeploying the whole thing.
- Custom RPC: you roll your own HTTP contract between agents. Fine for one pair of agents, but it doesn't scale to a mesh. Every new agent pair needs a new contract.
- Shared queues: Kafka, SQS, etc. Work fine operationally but lose the request-response semantics you actually want — you can't easily say "wait for this agent to finish and give me the result".
The three bad options without A2A
Monolithic agents bloat with every new capability and become impossible to test in isolation. Custom RPC between agent pairs works for one pair — then you have N×M contracts to maintain as the mesh grows. Shared queues (Kafka, SQS) lose the request-response semantics you need: you can't easily say "wait for this agent to finish and give me the result." None of them scale.
A2A is the missing layer. It gives you a standard contract for "here's a task, go do it, tell me when you're done" — without either side needing to know anything about the other's internals.
How A2A works¶
A2A reuses standards your infrastructure already handles: HTTP for transport, JSON-RPC 2.0 for the payload shape, and Server-Sent Events for streaming results on long-running tasks.
The flow is:
- Discovery — the client agent fetches the remote agent's Agent Card from a known endpoint (or a registry). The card declares what tasks the remote agent handles and how to authenticate.
- Task submission — the client sends a JSON-RPC request with the task description and any input data.
- Streaming progress — for tasks that take time (a deployment, a code review, an infra plan), the remote agent streams status updates via SSE. No polling, no timeouts.
- Result delivery — on completion, the remote agent returns a structured response. The client agent continues with the result.
// Minimal A2A task request (JSON-RPC 2.0)
{
"jsonrpc": "2.0",
"method": "tasks/send",
"id": "task-001",
"params": {
"id": "task-001",
"message": {
"role": "user",
"parts": [
{
"type": "text",
"text": "Check if ArgoCD application 'payments-prod' is healthy and return the sync status."
}
]
}
}
}
// Agent Card — what the remote agent advertises about itself
{
"name": "argocd-ops-agent",
"description": "Handles ArgoCD status checks, sync triggers, and rollback operations",
"url": "https://agents.platform.internal/argocd",
"version": "0.3.1",
"capabilities": {
"streaming": true,
"pushNotifications": false
},
"skills": [
{
"id": "argocd-status",
"name": "Application status check",
"description": "Returns sync and health status for a named ArgoCD application"
},
{
"id": "argocd-sync",
"name": "Trigger sync",
"description": "Triggers a hard refresh and sync for a named application"
}
]
}
A2A v1.0 is production-stable
150+ organisations including AWS, Microsoft, Salesforce, SAP, and ServiceNow are running A2A v1 in production as of April 2026. The transport is HTTP + JSON-RPC 2.0 + SSE — nothing exotic. If your infrastructure handles standard HTTP services, it handles A2A. No custom message bus, no proprietary SDK lock-in.
A2A v1.0 adds cryptographic signing to Agent Cards. The client agent can verify that a card was issued by the agent it expects — this matters most when agents from different teams or organisations are communicating. An unsigned card is fine inside a single trusted namespace; across team or org boundaries, signing is how you prevent a rogue service from impersonating a legitimate agent.
MCP and A2A together¶
The natural split for a platform team looks like this:
MCP connects your agents to your platform's tools — the ArgoCD MCP server, the Kubernetes MCP server, the GitHub MCP server, your internal Crossplane claim API. An agent uses MCP to read cluster state, trigger syncs, query events.
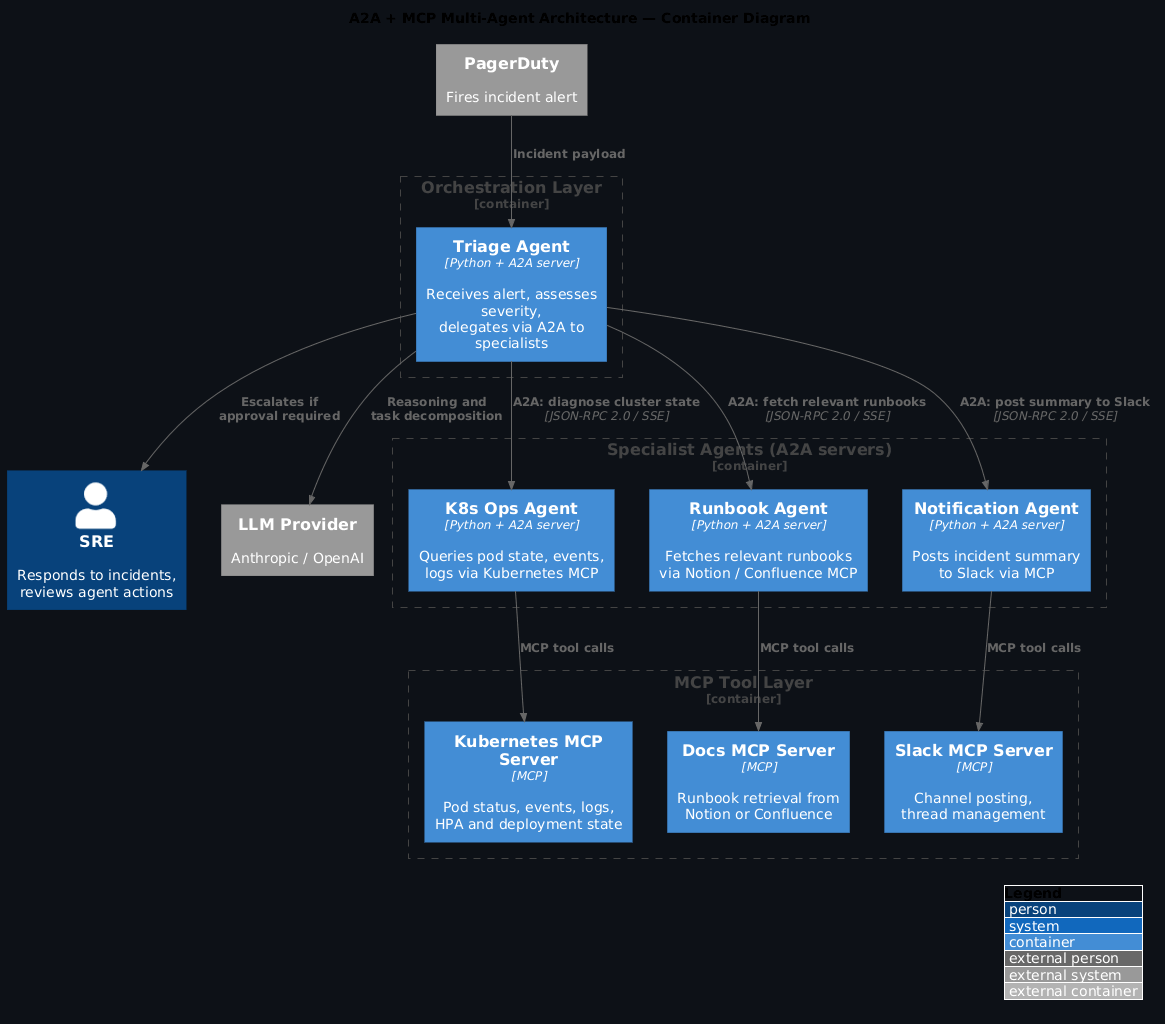
A2A connects specialised agents to each other. In a multi-agent incident response workflow:
[PagerDuty alert]
|
v
[Triage agent] --A2A--> [K8s ops agent] --MCP--> [Kubernetes MCP server]
|
+--A2A--> [Runbook agent] --MCP--> [Notion / Confluence MCP server]
|
+--A2A--> [Notification agent] --MCP--> [Slack MCP server]
The triage agent doesn't need to know how to query Kubernetes. It doesn't need credentials for your cluster. It just knows there's a K8s ops agent that can handle that task and return a structured result. The K8s ops agent, in turn, uses MCP to talk to Kubernetes. Neither layer knows about the other's implementation.
The trust boundary is the key insight
The SRE team builds and operates the K8s ops agent without ever exposing cluster credentials to the product team running the triage agent. The platform team builds a runbook agent and offers it to every team that needs incident context, without those teams needing access to the underlying Confluence or Notion workspace. The A2A layer is where the capability crosses the trust boundary — cleanly, with a structured contract and an audit trail.
This trust boundary is why A2A matters most in larger organisations. An SRE team can build and operate the K8s ops agent without ever exposing cluster credentials to the product team that runs the triage agent. A platform team can build a runbook agent and offer it to every team that needs incident context, without those teams needing access to the underlying Confluence or Notion workspace. The A2A layer is where the capability crosses the trust boundary — cleanly, with a structured contract and an audit trail.
What you need to run A2A on Kubernetes¶
An A2A server is just an HTTP service that implements the tasks/send JSON-RPC method and streams SSE responses. You can wrap any existing agent in an A2A interface with a thin HTTP adapter.
apiVersion: apps/v1
kind: Deployment
metadata:
name: argocd-ops-agent
namespace: platform-agents
spec:
replicas: 2 # stateless — A2A doesn't require session affinity
selector:
matchLabels:
app: argocd-ops-agent
template:
metadata:
labels:
app: argocd-ops-agent
spec:
containers:
- name: agent
image: platform/argocd-ops-agent:0.3.1
ports:
- containerPort: 8080
env:
- name: ARGOCD_SERVER
valueFrom:
secretKeyRef:
name: argocd-credentials
key: server-url
---
apiVersion: v1
kind: Service
metadata:
name: argocd-ops-agent
namespace: platform-agents
spec:
selector:
app: argocd-ops-agent
ports:
- port: 80
targetPort: 8080
For Agent Card hosting, the simplest approach is to mount the card JSON as a ConfigMap and serve it at /.well-known/agent.json from the same HTTP server. Then any discovery crawler just hits that path across all services in your platform-agents namespace to build the registry.
For authentication between agents, A2A v1.0 specifies OAuth 2.1 flows. If you're already running SPIFFE/SPIRE for workload identity, you can use the SVID as the credential rather than managing a separate secret — the SVID proves which agent is making the request without any static secrets in your manifests.
Stateless by design — deploy like any other microservice
A2A doesn't require session affinity. Tasks submit over standard HTTP. Results stream via SSE. Deploy with standard HPA, standard rolling updates, standard Kubernetes ingress. No special handling, no Redis sidecar for session state, no custom load balancer config. If you know how to run a stateless HTTP service, you know how to run an A2A agent.
The stateless design is worth calling out: because A2A tasks are submitted over standard HTTP and results stream via SSE, you don't need sticky routing. Your A2A agents deploy exactly like any other Kubernetes workload. Standard HPA, standard ingress, no session affinity in your Service or Ingress config.
How this fits the broader stack¶
The KubeCon EU 2026 session on MCP and ArgoCD showed the pattern of using MCP to give agents access to ArgoCD operations. A2A is the next layer: an orchestrating agent that delegates ArgoCD-specific tasks to a specialised ArgoCD agent, without coupling the two together or sharing credentials.
HolmesGPT already does a version of agent delegation internally — root cause analysis by dispatching specialised investigation steps. A2A is the standard protocol that lets you build that pattern across agents you didn't write and teams you don't control.
And from a governance angle: a policy-as-code layer can intercept A2A task requests and validate them against OPA or Kyverno policy before forwarding to the target agent. Every A2A request is a structured JSON-RPC call, which means policy evaluation is deterministic and the decision is loggable. That's a meaningful security primitive for regulated environments where you need an audit trail of every inter-agent action.
What you get¶
- Agent specialisation without coordination spaghetti — each agent does one thing well and delegates the rest
- Cross-team agent reuse without sharing credentials or internal context
- A standard audit trail: every A2A task request and response is a structured, loggable JSON-RPC call
- An architecture that absorbs new agents without changing existing ones
FAQ¶
Is A2A production-ready?
v1.0 is a stable spec under the Linux Foundation with 150+ organisations including AWS, Microsoft, Salesforce, and ServiceNow running it in production as of April 2026. The spec itself is stable. The tooling ecosystem — SDKs, agent frameworks with native A2A support — is maturing fast but not as complete as MCP's yet. Start with the Python or TypeScript SDK if you're building new agents; wrapping existing agents with a thin A2A HTTP adapter is lower risk than adopting a full framework.
Does A2A replace service meshes like Istio or Linkerd?
No, and it doesn't try to. A2A is an application-layer protocol — it defines the shape of the request and response between agents. A service mesh handles the infrastructure layer: mTLS, traffic management, circuit breaking, observability. You'd run both: A2A for agent-to-agent semantics, your existing mesh for the security and reliability properties. They compose rather than compete.
How does A2A handle long-running tasks?
Via SSE streaming. When you submit a task that will take more than a few seconds, the remote agent keeps the HTTP connection open and streams progress updates as Server-Sent Events. The client agent can display progress, cancel if needed, or just wait for the final result. This is more elegant than polling and avoids the timeout problems you get with long-running synchronous HTTP calls.
What happens if the remote agent is unavailable?
A2A doesn't define a retry or queue mechanism at the protocol level — that's intentional, since different deployments have different reliability requirements. In practice, most A2A implementations sit behind a standard Kubernetes Service, so you get the reliability properties of that layer (readiness gates, liveness probes, multiple replicas). For genuinely async tasks where you can't afford to lose the request, wrapping the A2A call in a queue-backed workflow is a reasonable pattern.
Sources: - A2A v1.0 announcement - A2A specification - GitHub: a2aproject/A2A - Google Developers Blog: A2A launch