

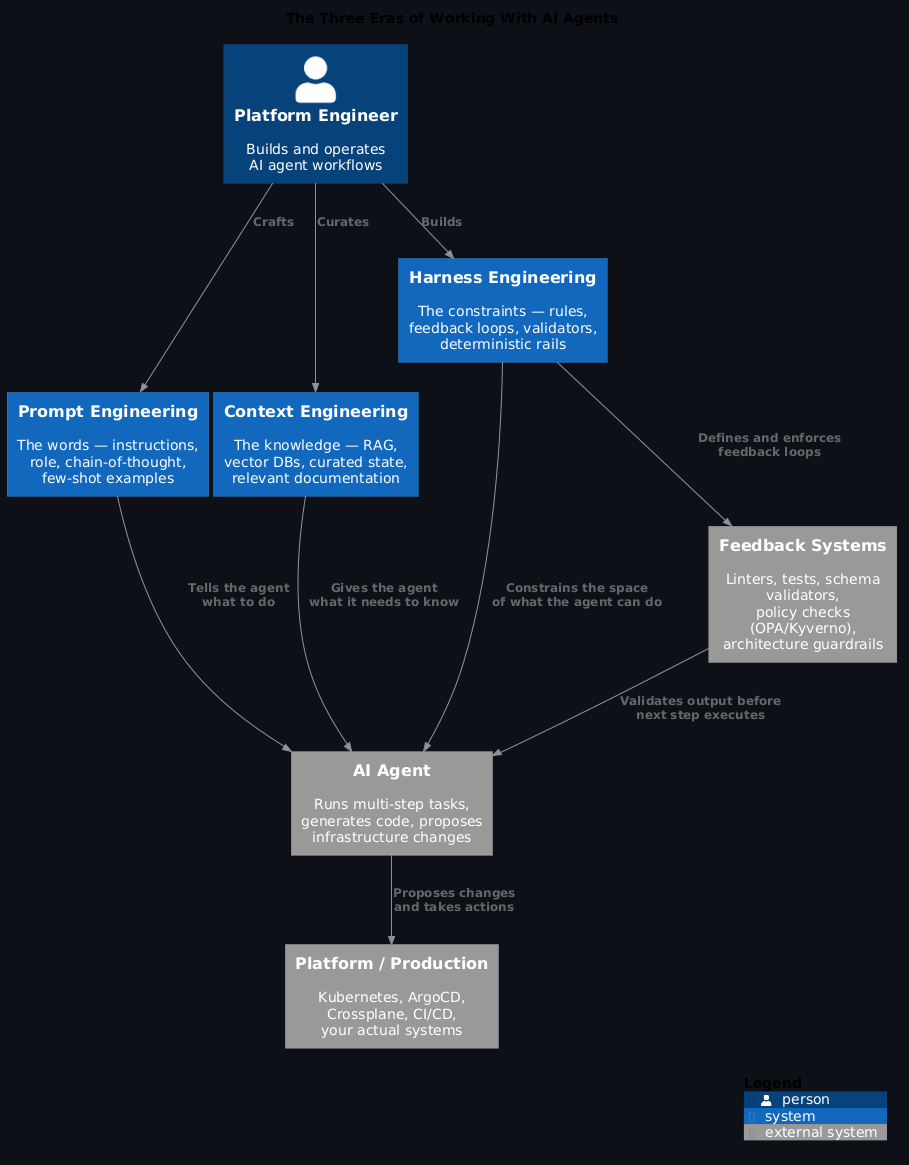
From Prompt to Harness: The Three Eras of Working With AI¶
There's a moment every team hits after they've been running AI in production for a few months. The demos worked great. The initial results were impressive. And then the cracks appeared.
The agent ignored your naming conventions. It generated code that violated an architectural boundary you thought was obvious from context. Two parallel agent sessions clobbered each other's work. You added more detail to the prompt. You tuned the context window. And it still happened — not always, not predictably, but enough to matter.
What you ran into is the gap that neither prompt engineering nor context engineering was designed to close. And in 2026, there's a name for the discipline that closes it: harness engineering.

Era one: Prompt engineering (2023–2024)¶
Prompt engineering was about learning to talk to the model. Chain-of-thought. Few-shot examples. Role assignment. System prompts. The discovery that "think step by step" genuinely improved outputs. The art of phrasing.
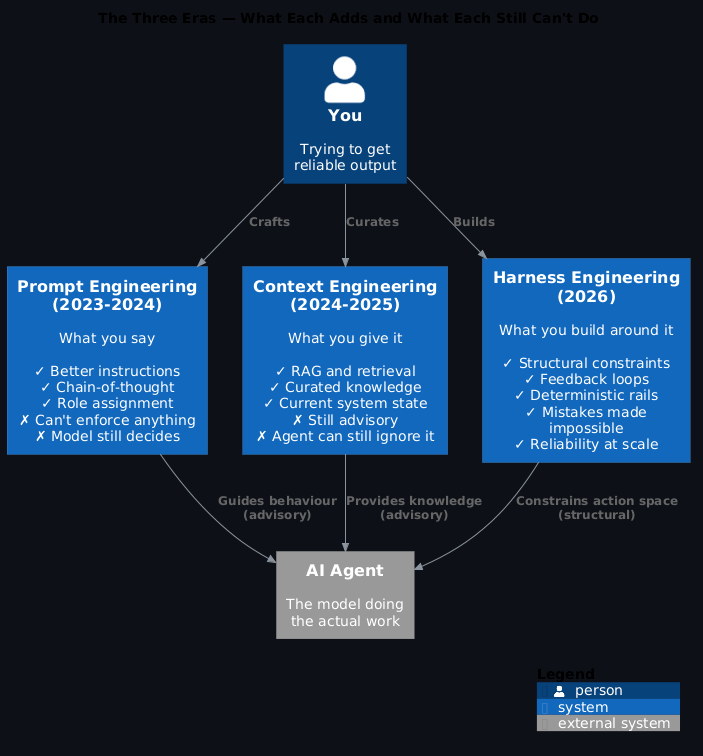
It worked. It still works, actually. A well-crafted prompt outperforms a sloppy one by a meaningful margin. But prompt engineering assumed the model would figure out the rest. Give it good instructions, trust it to execute. That assumption scaled fine for simple, single-turn tasks. It started breaking down the moment tasks became multi-step, multi-agent, or ran unsupervised in production.
The problem isn't that prompts are bad. It's that a prompt is just words. Words don't enforce anything. The model reads them and does its best — which is usually good, but "usually good" isn't production reliability.
The prompt engineering failure mode
Words don't enforce anything. A prompt is instructions the model reads and tries to follow — not constraints it's mechanically bound by. "Usually good" isn't production reliability. Every time you've seen an agent ignore a naming convention or violate an architectural boundary despite clear instructions, this is why.
Era two: Context engineering (2024–2025)¶
Context engineering was the recognition that the model's output is only as good as what you put in its context window. Not just the instructions, but the knowledge. The right documentation, the right examples, the current state of the system, the user's history, the relevant code.
This is where RAG took off, where vector databases became infrastructure, where teams started thinking carefully about what to include in the context and in what order. The insight was: the model doesn't know what it doesn't know. Give it better raw material and it'll produce better results.
And again — this is still correct and still essential. Context engineering is a real skill and it matters. The problem is that it's still fundamentally about what you tell the model. You're curating the information the agent works from, but you're not constraining the space of actions it can take or the outputs it can produce.
A well-informed agent that ignores your architectural conventions is still an agent that ignores your architectural conventions.

Era three: Harness engineering (2026)¶
Mitchell Hashimoto — the person who built Terraform, who's thought harder about infrastructure as code than almost anyone — described what he started doing in early 2026: "Any time you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again."
Hashimoto's rule
"Any time you find an agent makes a mistake, you take the time to engineer a solution such that the agent never makes that mistake again." Not "add more instructions." Not "improve the prompt." Engineer a constraint. Close the loop mechanically. This is the discipline that separates harness engineering from prompt tuning.
That's harness engineering in one sentence. Not "add more instructions," not "give it better context." Engineer a constraint. Build a feedback loop. Make the mistake mechanically impossible, or at least detectable before it ships.
A harness is the full environment around an agent — the scaffolding, constraints, feedback loops, and verification systems that let it do reliable work. Here's the surprising finding: constraining an agent's solution space actually increases its reliability and productivity. You're not hobbling it. You're removing the ambiguity that causes it to go wrong.
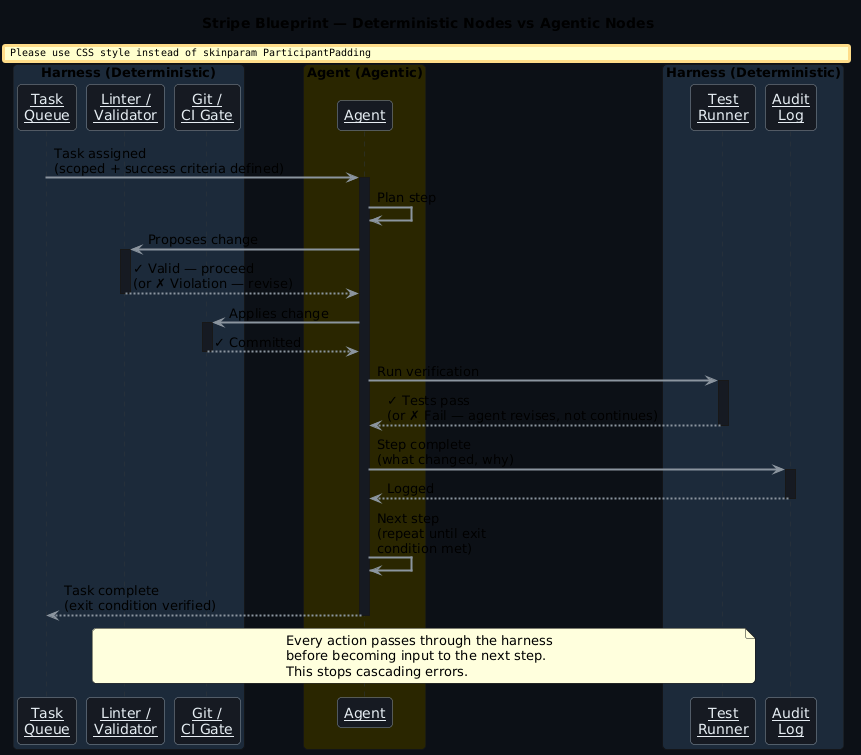
Stripe ships roughly 1,300 AI-written pull requests every week. They're not doing that with better prompts. They separate workflows into deterministic nodes — run a linter, push a commit, check a test suite — and agentic nodes — implement a feature, fix a CI failure, write a migration. The harness handles the deterministic parts with zero AI involvement. The agentic parts run with real constraints: architectural guardrails, linters that catch violations before they reach review, machine-readable rules that encode decisions the agent shouldn't be making itself.
The most surprising finding from 2026 is this: swapping the harness changes SWE-bench scores by 22 points. Swapping the model changes them by 1 point. The harness matters more than the model. Let that sink in.
The finding that changes everything
Swapping the harness changes SWE-bench scores by 22 points. Swapping the model changes them by 1 point. The harness — not the model, not the prompt — is the primary driver of agent reliability in production. If you're optimising your model selection, you're optimising the wrong variable.

What a harness actually looks like¶
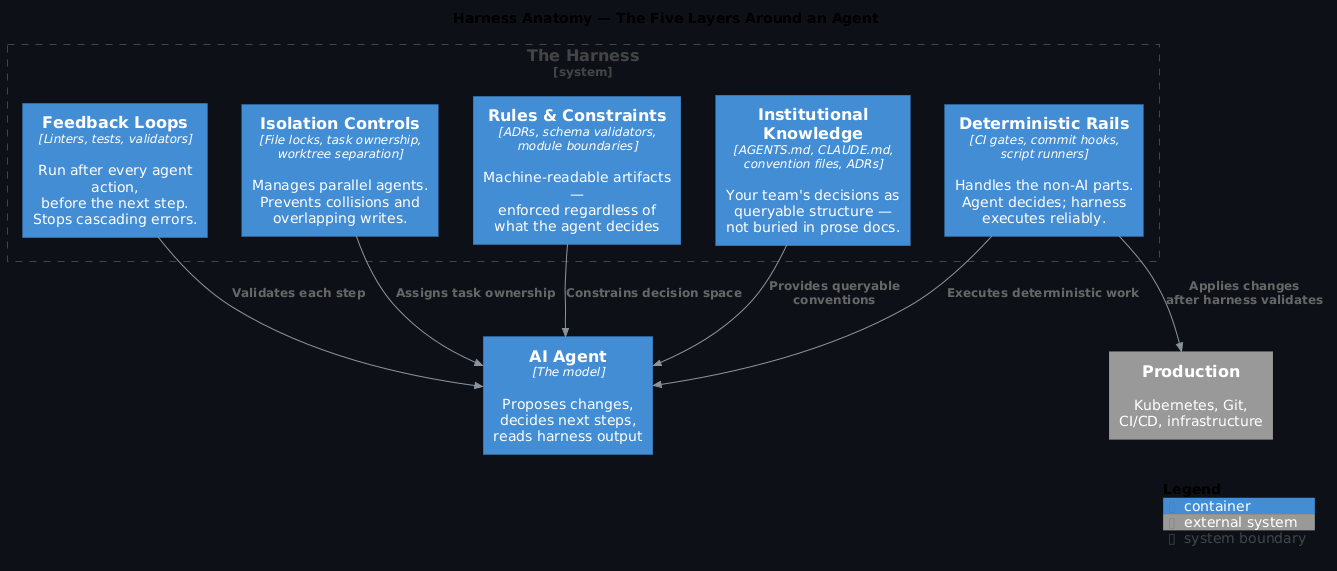
It's not one thing. It's a set of layers:
Rules and constraints — machine-readable artifacts that encode what the agent shouldn't do. Architecture decision records the agent can query. Schema validators. Module boundary definitions. Not as context the agent might choose to follow, but as checks that run regardless of what the agent decides.
Feedback loops — linters, tests, and validators that run after every agent action and before the next one. The agent proposes a change, the harness validates it, the agent sees the result. This is how you stop cascading errors — every step is checked before it becomes input to the next step.
Deterministic rails — the parts of your workflow that don't need AI should be handled by code, not left to the agent. Stripe's Blueprint pattern is the clearest example: separate the "decide what to do" step (agentic) from the "do it correctly" step (deterministic). The agent decides, the harness executes reliably.
Isolation and parallelism controls — agents running in parallel need to understand what they own. File locks, task ownership, workspace isolation. The harness manages this so the agents don't collide.
Institutional knowledge as structure — your team's conventions, patterns, and decisions encoded as queryable artifacts rather than buried in documentation the agent may or may not surface. AGENTS.md files, structured ADRs, convention files the agent checks before acting.

Why this matters for platform engineering specifically¶
If you're building platforms, you're in a particularly interesting position with harness engineering. You're probably already thinking about this — you just haven't called it that.
Every time you write a policy as OPA or Kyverno rather than hoping developers follow the docs, you're doing harness engineering. Every time you build a CI gate that rejects non-compliant infrastructure before it hits the cluster, you're building a harness. The principle is identical: don't rely on the human (or the agent) to follow the rules; enforce the rules structurally.
Apply this to your platform agents
Every time you write a policy as OPA or Kyverno rather than hoping developers follow the docs, you're already doing harness engineering. The same principle applies to your agents: don't rely on them to follow the rules, enforce the rules structurally. What it can query, what it can write, what gets validated before anything applies, what requires human approval.
What changes in 2026 is that your platform agents — the things doing drift detection, generating resources, proposing infrastructure changes, triaging incidents — need the same treatment. An agent that can touch your production infrastructure is not something you guide with a well-crafted prompt and hope for the best. You build a harness: what it can query, what it can write, what gets validated before anything applies, what requires human approval.
The good news is the mental model transfers directly. You've been thinking about infrastructure as code for years. Harness engineering is just agents as code — the same principle of making the desired behaviour enforceable, not optional.
The three eras aren't sequential — you need all of them¶
Here's what I want to be clear about: harness engineering doesn't replace prompt engineering or context engineering. It completes the picture.
You still need a well-crafted prompt. You still need to give the agent the right context — the right docs, the right state, the right examples. And then you build the harness that makes the whole thing reliable at scale.
Prompt engineering taught us how to talk to the model. Context engineering taught us what to give it. Harness engineering teaches us how to build around it.
If you're running AI agents in production and you haven't thought about the harness yet, that's your next conversation. Not "what model should we use" or "how do we prompt it better." What constraints can we build? What feedback loops can we add? What does the agent have to prove before it takes the next step?
That's where the reliability comes from. Not from the model, not even from the prompt. From the harness.
Where harness engineering goes next¶
Harness engineering is early. The tooling is still rough, the patterns are still being discovered, and most teams are somewhere between "we've heard of this" and "we're building it ad hoc." But the direction is clear, and a few things are already visible on the horizon.
Harnesses will become first-class artefacts. Right now, most harnesses are implicit — a linter here, a CI gate there, a CLAUDE.md that someone wrote six months ago and hasn't touched since. The next step is treating the harness the way we treat infrastructure: versioned, tested, deployed, monitored. Your harness gets a changelog. It gets a test suite that verifies the constraints work. It gets observability so you can see which rules fired, which feedback loops caught errors, and where the agent is consistently hitting the same wall.
Self-improving harnesses. Hashimoto's rule — "any time an agent makes a mistake, engineer a solution such that it never makes that mistake again" — currently requires a human to close the loop. The natural evolution is that the agent surfaces its own failure patterns and proposes harness improvements. Not autonomously, but as a structured feedback signal: here's the category of mistake I keep making, here's a constraint that would prevent it, do you want to add it? The human approves the constraint. The harness improves. Fewer human hours per reliability gain over time.
A2A-aware harnesses. As agents start coordinating across systems via the A2A protocol, the harness has to cross system boundaries too. A constraint defined in your internal harness needs to be visible to external agents that delegate tasks to yours. An Agent Card isn't just capability discovery — it's harness discovery. What are the rules this agent operates under? What will it refuse to do? What does it validate before acting? The harness becomes part of the public interface.
Harness standards for regulated industries. Finance, healthcare, legal — anywhere that AI agents touch high-stakes decisions — will need harnesses that satisfy regulatory requirements, not just engineering best practices. Audit trails that meet specific standards. Approval gates that map to compliance frameworks. Constraints that can be inspected by auditors who don't know what a linter is. This is nascent but inevitable, and platform teams who build harness infrastructure now will be ahead of it.
The broader arc is this: we're moving from AI as a capability you prompt carefully to AI as infrastructure you engineer deliberately. The harness is the engineering layer that makes that shift real. It's the difference between "we use AI" and "we operate AI reliably."
That's a different discipline. And it's just getting started.
FAQ¶
Does harness engineering replace prompt engineering?
No — all three eras are needed. Prompt gives instructions, context gives knowledge, harness gives reliability. A well-crafted prompt still outperforms a sloppy one. Good context still produces better outputs. The harness is what makes the combination reliable at scale. You need all three layers working together.
What's the simplest harness you can build today?
Start with an AGENTS.md that lists forbidden paths and a CI linter that validates agent PRs. That's two constraints. That's a harness. You don't need a full observability pipeline and automated rollback on day one. Encode one rule mechanically, see it catch a mistake, then add the next. The harness grows incrementally.
Is this only relevant for coding agents?
No — infrastructure agents, triage agents, drift detection agents all benefit from the same constraint-and-feedback-loop approach. Any agent taking actions in your environment needs guardrails on what it can touch, feedback loops that catch mistakes before they cascade, and deterministic rails for the parts of the workflow that don't need AI judgment at all.
Harness engineering as a term was introduced by Mitchell Hashimoto in February 2026. The Stripe Blueprint architecture is documented in their engineering blog. The 22-point SWE-bench harness vs. model finding is from research published in early 2026.