

Your AGENTS.md Is Great. Now How Do You Roll It Out to 40 Repos?¶
Writing one AGENTS.md is a solved problem. You commit the file, the agents read it, the naming convention incident stops happening. Done.
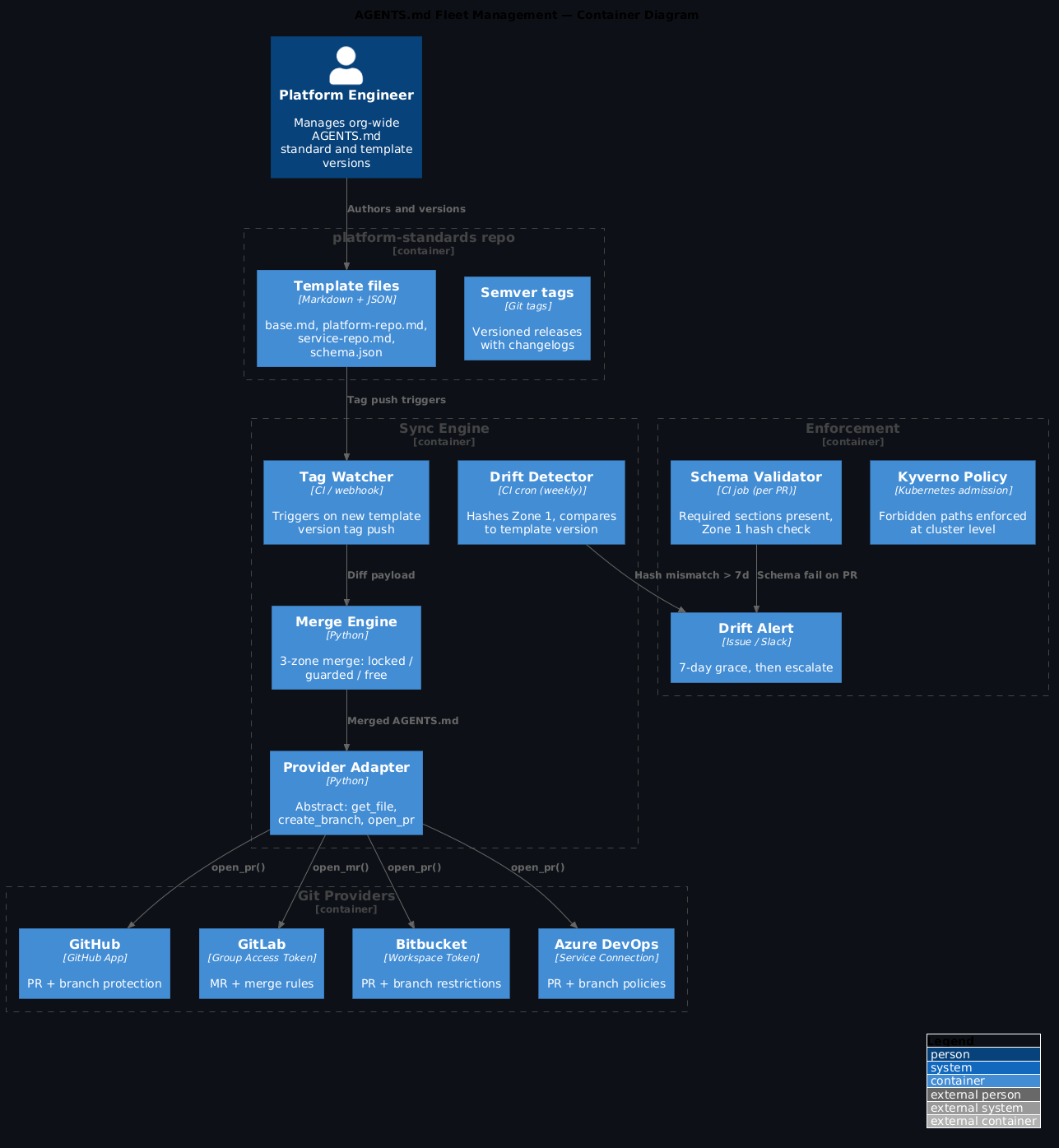
Then someone asks: "Should all our repos have this?" And you say yes. And now you have 40 repos across three teams, some on GitHub, some on GitLab, one stubborn service still on Bitbucket — and the question of how you keep them consistent, how you propagate updates when the org-level conventions change, and how you know when a repo has drifted from the standard.
That's the harder problem, and it looks a lot like every other configuration management problem you've already solved for your infrastructure. The same instincts that made you reach for GitOps and policy-as-code apply here.

Quick takeaways¶
- The three-zone file structure (locked / guarded / free) lets you own the safety-critical sections without blocking teams from extending the file for their needs
- A provider-agnostic sync engine exposes three abstract operations —
get_file(),create_branch(),open_pr()— that work identically across GitHub, GitLab, Bitbucket, and Azure DevOps - Schema validation in CI catches missing required sections before they merge; Kyverno catches the runtime consequences that don't depend on the file being read correctly
- Drift detection with a 7-day grace period balances enforcement with autonomy — teams get time to review and merge sync PRs, not instant blocks
The problem at scale¶
A single AGENTS.md in a single repo is just a file. At scale, it's a distributed configuration system — and distributed configuration systems drift.
Here's what drift looks like in practice. Six months after you rolled out AGENTS.md across the org, you rename a team and need to update the namespace pattern in every repo. Or you add a new forbidden path because a third-party provider now manages those CRDs. Or you discover that three repos have quietly edited the "sync is live" section to remove the warning about auto-deploy — because someone found it annoying.
Any of these happens constantly in a living platform. The question isn't whether your AGENTS.md files will diverge. It's whether you'll know when they do and have a clean way to resync them.
The invisible drift problem
The agent reads your AGENTS.md at the start of every session. If the file has drifted from the org standard — missing a forbidden path, wrong namespace pattern, outdated sync model statement — the agent is working from incorrect context. It fails silently. No error, no warning. The protection you thought you had is just not there.
The three-zone file structure¶
The foundation of the fleet management pattern is a structured AGENTS.md format that distinguishes between three types of content:
<!-- ZONE 1: ORG — managed by the platform team. Do not edit. -->
## Sync model
Changes merged to `main` are live within ~90 seconds via ArgoCD auto-sync.
There is no staging buffer between a merged PR and a running cluster.
## Forbidden paths
- `crds/` — managed by the upgrade-crds pipeline
- `infra/providers/` — managed by the bootstrap workflow
<!-- END ZONE 1 -->
<!-- ZONE 2: TEAM — extend or override for your team. Changes reviewed on sync. -->
## Team conventions
[team-specific naming patterns, tools, escalation paths]
<!-- END ZONE 2 -->
<!-- ZONE 3: REPO — no restrictions -->
## This repo
[anything repo-specific]
Zone 1 is locked. The sync engine will overwrite any edits to it on the next template version bump. If someone on a team edits Zone 1 to remove the auto-deploy warning, the next sync PR restores it. No conversation needed — the policy is structural, not social.
Zone 2 is guarded. If the template changes Zone 2 content, the sync PR flags it explicitly for team review. Teams can override Zone 2 defaults, but they're made aware when the org standard changes underneath them.
Zone 3 is free. Teams own it entirely. The sync engine never touches it.
Zone 1 is policy, not documentation
The safety-critical sections — sync model, forbidden paths, secrets handling — live in Zone 1 because they're not suggestions. They're constraints that apply regardless of what the team thinks. The zone structure is how you make that distinction explicit and machine-enforceable rather than a convention that depends on people reading the comments.
The sync engine¶
The sync engine is a small service (or CI job) that runs on every new version tag in your platform-standards repo. It needs to know three things: what the new template says, which repos are in scope, and how to open a PR on each one.
The provider abstraction exposes three operations:
class GitProvider(Protocol):
def get_file(self, repo: str, path: str, ref: str) -> str: ...
def create_branch(self, repo: str, branch: str, base: str) -> None: ...
def open_pr(self, repo: str, branch: str, title: str, body: str) -> str: ...
Each git provider implements these three operations. The merge logic — which compares Zone 1 content and builds a diff — is identical regardless of provider. You write it once.
def sync_repo(repo: str, provider: GitProvider, template: Template) -> None:
current = provider.get_file(repo, "AGENTS.md", "main")
merged = merge_zones(current, template)
if merged == current:
return # already up to date
provider.create_branch(repo, f"agents-md-sync/{template.version}", "main")
provider.commit_file(repo, "AGENTS.md", merged, f"agents-md-sync/{template.version}")
provider.open_pr(
repo,
branch=f"agents-md-sync/{template.version}",
title=f"chore: sync AGENTS.md to platform-standards v{template.version}",
body=render_pr_description(current, merged, template),
)
The PR description matters. It should clearly show which zones changed and why — a diff of Zone 1 sections with the changelog entry from platform-standards. Teams are more likely to review and merge sync PRs when they can see exactly what changed and that their Zone 3 content is untouched.
Apply this: auto-close stale sync PRs
When a new template version ships before the previous sync PR was merged, close the old PR automatically and open a fresh one against the new version. Otherwise repos accumulate a stack of open sync PRs that nobody reviews. One open PR per repo at any time keeps the signal clean.
Per-provider implementation notes¶
All four major providers support the three abstract operations, but the auth model and API shape differ:
GitHub — use a GitHub App with contents:write and pull_requests:write permissions on the repos in scope. GitHub Apps handle token rotation automatically and support fine-grained repo access. Avoid personal access tokens for org-wide automation.
GitLab — use a Group Access Token with api scope. This gives you access to all repos within the group without per-project tokens. Merge requests on GitLab support allow_collaboration which lets the platform team push updates to the sync branch if the team hasn't picked it up.
Bitbucket — use a Workspace Access Token with repository:write and pullrequest:write. Note that Bitbucket's PR API returns a different shape from GitHub/GitLab — your provider abstraction handles this, but test the PR description rendering separately.
Azure DevOps — use a Service Connection with Code (Full) permissions. ADO's REST API uses refs/heads/ prefix conventions that differ from the others. The branch creation call is slightly different — worth wrapping this carefully in the abstraction.
Don't use personal access tokens for org-wide automation
PATs are tied to individual accounts. When that person leaves or their token expires, every sync job breaks. Use service accounts or machine identities (GitHub Apps, GitLab service accounts, ADO service connections) that aren't tied to a person.
Schema validation in CI¶
Every repo in scope gets a CI job that validates AGENTS.md against the schema on every PR. The schema is simple — it checks that required sections are present, not that their content is any particular string. You're enforcing structure, not content.
# .github/workflows/agents-md-validate.yml
name: Validate AGENTS.md
on: [pull_request]
jobs:
validate:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Validate AGENTS.md
run: |
npx @polarpoint/agentsmd-validator \
--schema https://raw.githubusercontent.com/your-org/platform-standards/main/schema.json \
--file AGENTS.md
The validator checks:
- Zone 1 markers are present and in the correct order
- Required sections (
## Sync model,## Forbidden paths,## Naming conventions,## Running tests) exist within Zone 1 ## Running testscontains at least one executable command (not just prose)- Zone 1 content hash matches the current template version (warning, not error — this is drift detection, not a hard block)
Drift detection¶
The sync engine opens PRs, but it can't force merges. Some teams will let sync PRs sit. The drift detector runs as a weekly CI job across all repos and reports:
repo template_version last_sync zone1_hash status
platform-core v1.4 2026-06-02 ✓ current OK
payments-service v1.4 2026-05-28 ✓ current OK
legacy-billing v1.2 2026-04-10 ✗ stale DRIFT (53 days)
data-pipeline v1.4 2026-06-01 ✓ current OK
The grace period is 7 days after a sync PR is opened. After 7 days with no merge, the detector opens a GitHub issue (or Jira ticket, or Slack message — whatever your team uses for platform alerts). After 30 days, it adds a label to all PRs from that repo warning reviewers that AGENTS.md is out of date. This is the escalation path that keeps drift from becoming permanent without blocking teams from working.
Hash Zone 1, not the whole file
The drift detector should compare the hash of Zone 1 content only, not the full file. Teams legitimately change Zones 2 and 3 — that's the point. A hash mismatch on the full file would generate false positives constantly. Only Zone 1 drift is a signal worth acting on.
Kyverno as the enforcement backstop¶
AGENTS.md is read by agents at session start. Kyverno runs at admission time and doesn't depend on the file at all — it enforces the consequences of the forbidden paths directly on the cluster.
The two layers work together: AGENTS.md tells the agent what not to touch, Kyverno prevents the resulting resource changes from being applied even if the agent ignored the file or the file was wrong. You need both because you can't fully trust either alone.
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: agentsmd-forbidden-paths
spec:
validationFailureAction: Audit
rules:
- name: block-crd-modification
match:
any:
- resources:
kinds: [CustomResourceDefinition]
validate:
message: >-
CRD modifications must go through the upgrade-crds pipeline.
See AGENTS.md Zone 1 for details.
deny:
conditions:
all:
- key: "{{ request.userInfo.username }}"
operator: NotIn
value: ["system:serviceaccount:platform-system:crd-upgrade-sa"]
Start every Kyverno policy in Audit mode. Watch the warnings for a week. You'll discover legitimate exceptions you didn't know about. Switch to Enforce only after the audit shows clean.
What you get¶
- Zone 1 content is structurally immutable — agents always get accurate sync model and forbidden path information regardless of whether teams modified the file
- One open sync PR per repo per template version, automatically created and auto-closed on supersession
- Weekly drift report surfaces repos that haven't merged sync PRs, with escalating alerts
- Kyverno enforces the forbidden paths at the cluster level, independent of the file content
- The same sync engine works across GitHub, GitLab, Bitbucket, and Azure DevOps — you write the merge logic once
FAQ¶
Do I need all four git providers, or can I start with just GitHub?
Start with whatever providers you actually use today. The provider abstraction makes it easy to add new ones later — you implement three methods and the rest of the engine is unchanged. Most orgs have one primary provider and one legacy one. Start with the primary, validate the pattern, then add the second.
What if a team wants to override a Zone 1 section for a legitimate reason?
Zone 1 overrides should go through a PR to platform-standards itself, not to the repo's AGENTS.md. If a team's repo has genuinely different sync semantics — say, it doesn't use ArgoCD — that's a Zone 1 template variant, not a per-repo exception. Add a non-argocd-repo.md template and let that repo use it. The principle: exceptions should be explicit and versioned, not silent edits.
How do we handle repos that aren't on our standard Git provider?
The provider abstraction handles this. As long as you can implement get_file(), create_branch(), and open_pr() for a provider, it integrates. For repos that use GitHub Enterprise on-prem or a self-hosted GitLab instance, the implementation is usually identical to the cloud version with a different base URL.
What's the right scope for Zone 1? How much should be locked?
Less than you think. Zone 1 should contain only the sections that are safety-critical for agents operating in production — sync model, forbidden paths, secrets handling pattern. If you lock too much, teams will work around the system entirely. The goal is to make the dangerous things immutable, not to control everything.
Does this pattern work for CLAUDE.md and .cursorrules too?
Yes, with minor adjustments. The zone structure and sync engine are the same. The schema validator just checks for different required sections. For CLAUDE.md specifically, Zone 1 would contain the Karpathy four-rules section — that's the bit that should be consistent across every repo regardless of team preference.
The platform-standards template repo structure, agentsmd-validator schema, and drift detector are available at github.com/polarpoint-io/ai-capabilities.