

AI in CI/CD: Safer Gates, Smarter Reviews¶
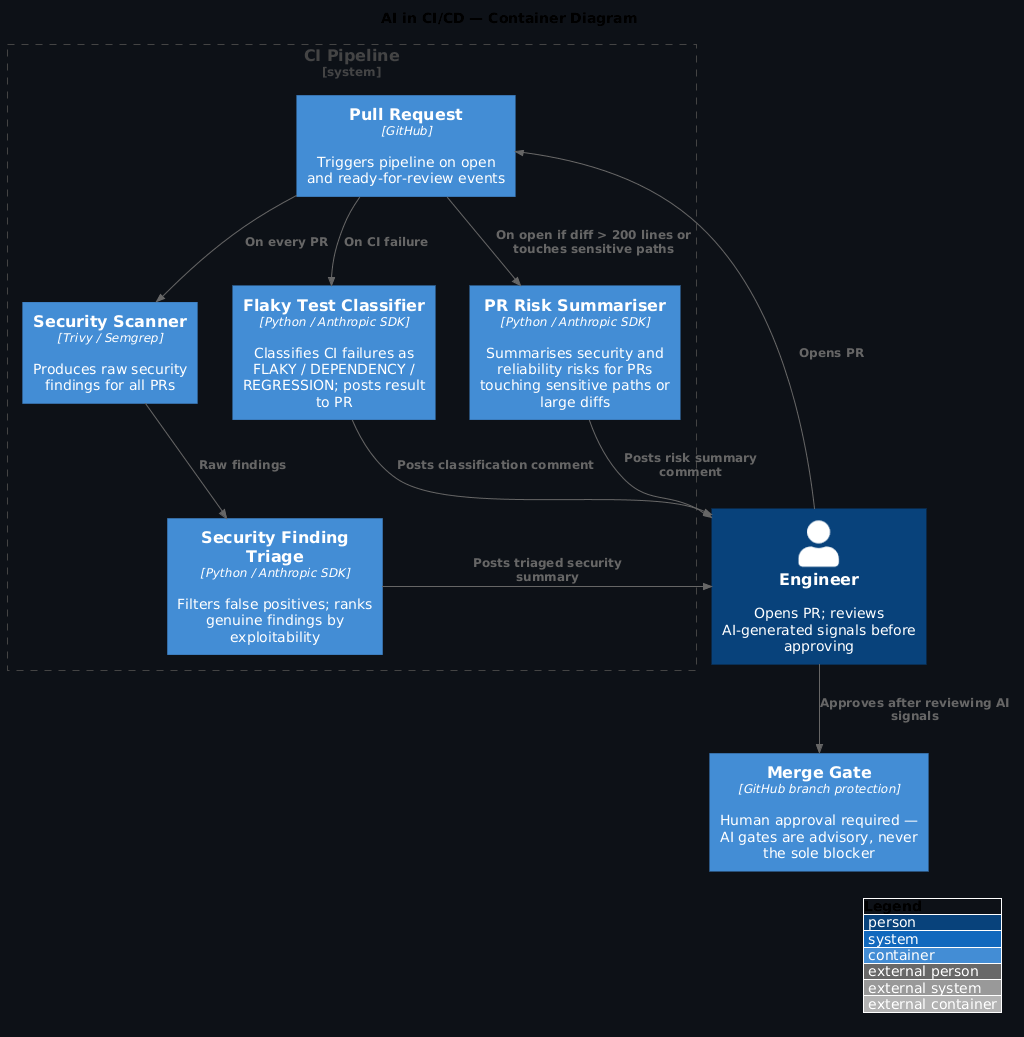
You know that moment when CI goes red, and before you've even clicked into the logs you already suspect it's that flaky database test again? Most CI failures fall into three buckets: flaky tests, dependency problems, and actual bugs. The problem is your CI output treats all three identically. Same red X, same block on merge, same engineer pulled out of flow to investigate something that was going to pass on retry anyway.
AI in CI isn't about replacing tests. It's about making the signal clearer. When CI fails, an engineer should know within 30 seconds whether this is worth their attention or whether it's a known transient failure. That's a classification problem. And AI is genuinely good at classification.
The same AI-first approach applies when failures get past the pipeline entirely — AI Incident Triage covers what to do after a bad deploy reaches production.

Quick takeaways¶
- Classification is the most reliable use of AI in pipelines — categorise failures before you escalate them to a human
- PR review assistance works when it's scoped tightly: risk flagging, not line-by-line criticism of style choices
- Security scan noise reduction is honestly where AI delivers the clearest ROI — the before/after is stark
- Never use AI to auto-approve or auto-merge. Keep humans in that loop, always.
Classification ROI is immediate
Teams that add flaky test classification typically see a 30–40% reduction in the time engineers spend investigating CI failures in the first month. The investment is a single GitHub Actions workflow and a 50-line Python script. The return is engineers who trust CI again instead of reflexively retrying.
What to use AI for (and what not to)¶
There's a pretty clear line between where AI genuinely helps in a pipeline and where it creates more problems than it solves.
Good uses: - Classifying test failures (flaky / dependency / real regression) - Summarising PR diffs with risk callouts - Filtering and prioritising security scan findings - Generating release notes from commit history
Bad uses: - Auto-approving PRs based on AI review - Running AI instead of tests — it's alongside them, not a replacement - Adding AI commentary on every PR regardless of complexity (review fatigue is real) - Using AI to decide whether to deploy to production
The pattern with the bad uses is pretty consistent: they either remove humans from decisions that need humans, or they add noise to a process that's already noisy enough.
Review fatigue is the silent killer
Applying AI review comments to every PR — including simple one-line changes — trains engineers to ignore them. Once engineers start skimming past AI comments, you've lost the signal value entirely. Gate the review on PR complexity and sensitive path coverage; apply it selectively and it stays trusted.
1) Test failure classification¶
When tests fail, the first question is always: is this a real failure or is this noise? Instead of making an engineer answer that question manually every time, let the classifier answer it first:
# .github/workflows/test-classification.yml
name: Test Failure Classification
on:
workflow_run:
workflows: ["CI"]
types: [completed]
jobs:
classify-failures:
if: github.event.workflow_run.conclusion == 'failure'
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Download test results
uses: actions/download-artifact@v4
with:
name: test-results
run-id: ${{ github.event.workflow_run.id }}
- name: Classify failures
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
PR_NUMBER: ${{ github.event.workflow_run.pull_requests[0].number }}
run: python scripts/classify-test-failures.py
# scripts/classify-test-failures.py
import anthropic
import json
import subprocess
client = anthropic.Anthropic()
def classify_failures(test_output: str, recent_history: list) -> dict:
"""Classify test failures using recent test history for context."""
# Check if these tests have failed before without a code change
historical_flakiness = check_flakiness_history(recent_history)
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=1024,
system="""Classify CI test failures. For each failed test, determine:
FLAKY: Failed before in recent history without related code changes
DEPENDENCY: Failure pattern suggests network, external service, or dependency issue
REGRESSION: New failure pattern consistent with the code changes in this PR
UNKNOWN: Cannot classify with available context
Output JSON: {"failures": [{"test": "...", "category": "...", "confidence": 0-1, "reason": "..."}],
"recommended_action": "...", "block_merge": true/false}
Set block_merge=false only if ALL failures are FLAKY or DEPENDENCY with high confidence.""",
messages=[{
"role": "user",
"content": f"""Test output:\n{test_output}\n\nHistorical flakiness data:\n{json.dumps(historical_flakiness)}"""
}]
)
return json.loads(response.content[0].text)
def post_classification_comment(pr_number: int, classification: dict):
"""Post a concise comment on the PR with the classification results."""
categories = {}
for failure in classification["failures"]:
cat = failure["category"]
categories[cat] = categories.get(cat, 0) + 1
summary = " | ".join(f"{cat}: {count}" for cat, count in categories.items())
if classification["block_merge"]:
action = "**Review required** - likely real regression"
else:
action = "**Can proceed** - failures classified as transient"
comment = f"""**CI Classification** ({summary})
{action}
| Test | Category | Confidence | Reason |
|------|----------|------------|--------|
""" + "\n".join(
f"| `{f['test']}` | {f['category']} | {int(f['confidence']*100)}% | {f['reason']} |"
for f in classification["failures"]
)
# Post comment via GitHub API
subprocess.run(["gh", "pr", "comment", str(pr_number), "--body", comment], check=True)
Apply this: require confidence scores
Prompt the classifier to output a confidence score (0–1) for each classification. Set block_merge=false only when ALL failures are FLAKY or DEPENDENCY with confidence ≥ 0.85. Below that threshold, default to showing the warning and letting a human decide. Calibrated uncertainty is more useful than false certainty.
2) PR risk summarisation¶
Not every PR needs an AI review. In fact, applying it to everything is one of the faster ways to make engineers stop trusting it. Use it selectively — PRs that touch security-sensitive paths, infrastructure code, or have a large diff. Here's how to gate it:
# .github/workflows/pr-risk-review.yml
name: PR Risk Review
on:
pull_request:
types: [opened, ready_for_review]
jobs:
risk-check:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
with:
fetch-depth: 0
- name: Check if review needed
id: check
run: |
# Count changed lines and check sensitive paths
LINES=$(git diff --stat origin/main...HEAD | tail -1 | awk '{print $4}')
SENSITIVE=$(git diff --name-only origin/main...HEAD | grep -cE "(auth|security|iam|secret|rbac|policy)" || true)
echo "lines=$LINES" >> $GITHUB_OUTPUT
echo "sensitive=$SENSITIVE" >> $GITHUB_OUTPUT
- name: Generate risk summary
if: steps.check.outputs.lines > 200 || steps.check.outputs.sensitive > 0
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
run: |
git diff origin/main...HEAD > /tmp/pr.diff
python scripts/pr-risk-summary.py
# scripts/pr-risk-summary.py (excerpt)
RISK_PROMPT = """Review this PR diff and identify specific risks.
Focus only on:
1. Security issues: exposed credentials, overly broad permissions, missing auth
2. Reliability risks: removed error handling, missing retries, hardcoded timeouts
3. Data risks: schema changes without migrations, missing indexes, unsafe queries
For each risk, provide: the file and line, what the risk is, and a suggested fix.
If there are no real risks, say so explicitly. Do not invent issues.
Keep the response under 200 words."""
Rule: AI review comments should flag, not nitpick. If it wouldn't block a human reviewer from approving the PR, the AI shouldn't flag it either. One useful thing beats five marginal things every time.
3) Security scan noise reduction¶
Here's an honest description of most security scanner output: a wall of findings, most of which are low-severity, informational, or outright false positives. Engineers learn to skim past them. And then — inevitably — a real finding gets skimmed past too.
AI can filter and prioritise before the findings ever reach a human reviewer:
# scripts/triage-security-findings.py
import anthropic
import json
client = anthropic.Anthropic()
def triage_findings(findings: list, context: dict) -> dict:
"""Filter and prioritise security scan findings."""
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=2048,
system="""You are a security triage assistant. You will receive security scan findings
and context about the codebase. Your job is to:
1. Remove obvious false positives (test data, intentional patterns, already-mitigated)
2. Rank the remaining findings by actual exploitability in this context
3. For each real finding, explain what an attacker could do with it
Output JSON: {
"critical": [{"id": "...", "description": "...", "impact": "...", "fix": "..."}],
"high": [...],
"dismissed": [{"id": "...", "reason": "..."}]
}
Be conservative: when uncertain, keep the finding rather than dismissing it.""",
messages=[{
"role": "user",
"content": f"Findings: {json.dumps(findings)}\n\nContext: {json.dumps(context)}"
}]
)
return json.loads(response.content[0].text)
def post_security_comment(pr_number: int, triaged: dict, raw_count: int):
critical = len(triaged["critical"])
high = len(triaged["high"])
dismissed = len(triaged["dismissed"])
if critical == 0 and high == 0:
body = f"""**Security scan: {raw_count} findings, {dismissed} dismissed as false positives**
No critical or high-severity issues requiring attention."""
else:
body = f"""**Security scan: {critical} critical, {high} high** ({dismissed} dismissed)
"""
for f in triaged["critical"]:
body += f"**CRITICAL** `{f['id']}` — {f['description']}\n> Impact: {f['impact']}\n\n"
For the policy layer that controls what an agent can actually change downstream of the pipeline, Policy as Code + Agents covers that in detail.
Conservative dismissal saves credibility
Prompt the security triage model with "when uncertain, keep the finding rather than dismissing it." A false negative that lets a real vulnerability through is far more damaging than a false positive that a human dismisses in 10 seconds. The value of the triage is reducing noise, not eliminating human review of genuine findings.
4) What you measure¶
If you add AI to CI, you need to actually know whether it's helping or just adding noise. Three metrics worth tracking:
- Classification accuracy: what percentage of FLAKY classifications turned out to be actual regressions when engineers investigated? Should be under 5% — if it's higher, the classifier is too trigger-happy
- Review comment acceptance: what percentage of AI risk flags did reviewers actually act on? If it's under 20%, the flags are too noisy and reviewers will start ignoring them
- Time to merge: did AI classification actually reduce the time engineers spend investigating false CI failures? This is the one that tells you if the whole thing is worth it
Measure these monthly. If they're not improving, your prompts or your thresholds need tuning — not more AI.
Apply this: instrument before you add more AI
Before expanding AI coverage to more pipeline stages, establish baselines for these three metrics. If you can't answer "did this actually help?" for the first gate you added, you'll have no basis for deciding whether the second one is working either. Measure first, expand second.
Frequently asked questions¶
Should AI be used to gate CI/CD deployments?
As an advisory layer, yes — classifying test failures, summarising PR risk, reducing security scanner noise. As the sole gate that blocks a deployment? No. The right setup is AI summaries paired with your existing CI checks, with a human making the final call. The AI gives you better signal; the human makes the decision.
How do you classify flaky tests with AI?
Feed the test name, failure message, and recent failure history to the model and ask it to classify as flaky, dependency failure, or genuine regression. The key is a structured prompt with explicit category definitions and a required confidence score — that makes the output consistent enough to act on automatically rather than just being interesting to read.
What's the risk of AI blocking a valid deployment?
False positives — the model flags something as high risk when it isn't. The mitigation is to treat AI output as a signal for human review, not a hard block. Never configure an AI gate to fail the build on its own without a human confirmation step. If you do, you're one bad classification away from a frustrated engineer who starts working around the gate entirely.
How do you measure whether AI CI gates are adding value?
Three things worth tracking: precision — what ratio of AI-flagged issues turn out to be genuine problems; cost of noise — how much time engineers spend investigating false positives; and signal value — how mean time to diagnosis has changed since you introduced the gate. All three together tell you whether you're actually ahead.
Should you apply AI review to every PR?
No — and this is where most teams go wrong. Apply it selectively: PRs touching security-sensitive paths, infrastructure code, or with large diffs (200+ lines). Applying AI commentary to every PR, including trivial one-line changes, trains engineers to ignore the comments. Selective application keeps the signal trusted.
What you get¶
- CI failures are classified before an engineer looks at them — they arrive with context, not just a red X
- PRs touching sensitive code get a targeted risk summary, not a generic AI opinion on everything
- Security findings are triaged before they reach a reviewer, so the real ones actually get seen
- The things that need human attention get it; the routine noise doesn't make it that far
Walkthrough files¶
.github/workflows/test-classification.yml— classify failures on CI run completionscripts/classify-test-failures.py— AI classification with flakiness history.github/workflows/pr-risk-review.yml— conditional PR review based on diff size and pathscripts/pr-risk-summary.py— targeted security and reliability risk flaggingscripts/triage-security-findings.py— filter and prioritise security scan output
If a build failure does make it through to production, AI Incident Triage picks up from there — it's the natural next step after this one.